I had the pleasure of attending a talk by Chris Mills, creator of the Opera Web Standards Curriculum, which was organised by those Standardistas fellas and Build. Chris was talking about HTML5 and one of the things I found interesting was the research behind how the HTML5 element names came about.
Google research
Google looked at something like a billion web pages and measured what ID and class names were used the most.
The results looked like this:
- footer
- menu
- title
- small
- text
- content
- header
- nav
- copyright
- button
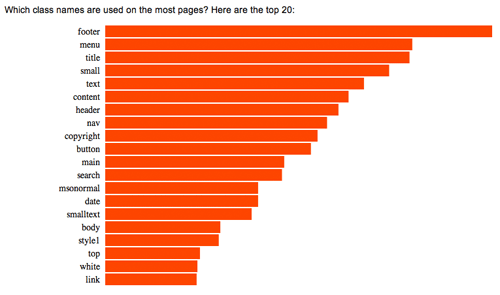
Look familiar?
Opera research
Opera then conducted their own research too, which came up with similar results.
Classes
- footer
- menu
- style1
- msonormal
- text
IDs
- footer
- content
- header
- logo
- container
And that's how HTML5 element names were decided
As you can see the new HTML5 element names were decided based on the most commonly used IDs and classes that web designers were already using.
Both ‘main’ and ‘content’ are the obvious omissions. I’m not 100% behind the reasoning for this but I guess ‘section’ and ‘article’ work better semantically for the main content areas.
Good to see ‘msonormal’ didn’t creep in there.
Receive more design content like this to your inbox
I promise not to spam you. No more than one email per week.